
Introduction
I’ve been struggling for a while to find a good central place to keep up with cybersecurity news. I tried RSS readers, I tried newsletters, I tried a few aggregator sites. Nothing really stuck. Either the UI annoyed me, or the sources were too broad, or I’d end up with the same story duplicated six times from six different outlets. I just wanted one clean place to see what’s going on in the threat landscape, on my own infrastructure, with the sources I actually trust.
So I built one. And before I get into how it works, I want to be upfront about something: I can code some, but I’m not a developer. This project was entirely vibe-coded with Claude. I knew what I wanted, I knew enough to steer the architecture in the right direction, and I let the AI do the heavy lifting on the implementation. I think that’s worth saying out loud, because there’s nothing wrong with it, and pretending otherwise would be a bit silly on a blog that also covers AI.
Dashboard
The dashboard aggregates cybersecurity news from a handful of the sources I actually trust, de-duplicates the flood of overlapping headlines, scores each article, and rolls everything up into a live DEFCON-style threat level. Green means the internet is having a chill day. Red means someone’s critical infrastructure is having a very bad one.
The threat gauge is the star of the show. It’s a custom SVG speedometer with a needle that swings through five color-coded zones, a 24-hour sparkline underneath, and a four-factor breakdown showing exactly why the score is where it is.
Tech stack
| Service | Tech | Port |
|---|---|---|
| Frontend | React 18 + Vite + Tailwind + Nginx | :3000 |
| API Gateway | Node.js 20 + Express | :4000 |
| News Aggregator | Python 3.12 + FastAPI + APScheduler | :8000 |
| Database | PostgreSQL 16 | :5432 |
| Cache | Redis 7 | :6379 |
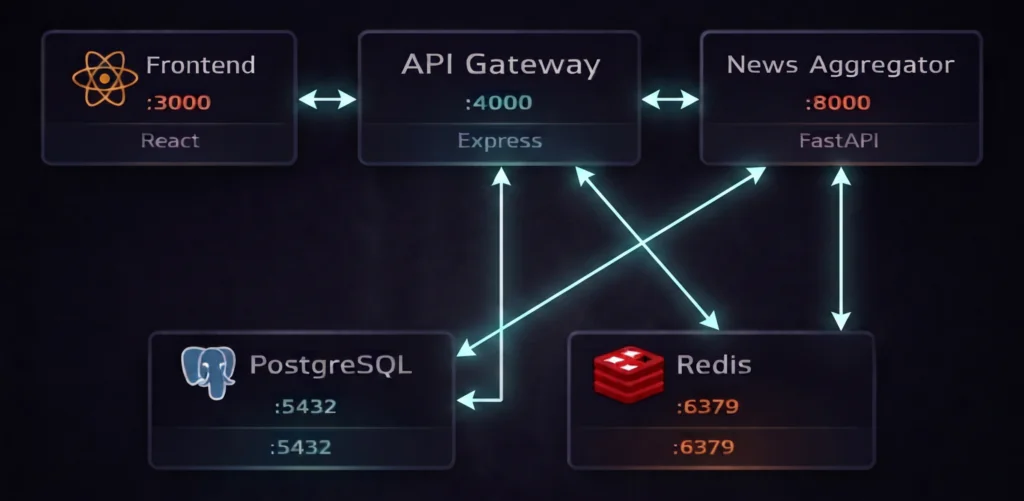
Everything runs in containers. PostgreSQL and Redis sit on an internal-only network with no external exposure. The front-end and API gateway live on a separate external network. If something in the aggregator blows up, it can’t reach the database directly; it goes through the API gateway.
networks:
internal:
driver: bridge
internal: true # postgres + redis: no external traffic
external:
driver: bridge # front-end + api-gatewayIt’s a small thing, but it’s the kind of network isolation that you don’t bother with until you’ve thought about what happens if one of your services gets compromised.
News sources
The aggregator pulls from five feeds I read anyway: Bleeping Computer (US), HackRead (UK), Security Affairs (IT), The Hacker News (India), The Register (UK). I read more, but I specifically chose these to have a non-US heavy source and a nice timezone spread.
Each feed has its own parser class that extends a shared BaseFeedParser abstract base:
class BaseFeedParser(ABC):
source_id: str
feed_url: str
@abstractmethod
async def fetch(self) -> list[RawArticle]:
"""Fetch and parse articles from this source."""
...Concrete implementations handle the quirks of each feed; some use RSS, some need HTML stripping, some bury the publication date in strange places. APScheduler kicks off a full fetch cycle every 60 minutes (configurable), plus an immediate run on startup so the dashboard isn’t empty when the container comes up.
De-duplication pipeline
This is still the part I’m most proud of, and it’s grown a few extra layers since launch. The structure remains the same two-layer design, but the thresholds and signals have been tuned based on real-world noise.
Layer 1 is a SHA-256 fingerprint of the normalized, stop-word-stripped title tokens, stored in a Redis SET with a 7-day TTL. O(1) lookup, runs on every article, costs nothing.
Layer 2 runs when L1 passes. It now checks four signals:
- Jaccard token overlap. Threshold 0.28 (tuned down from an earlier 0.35; the higher value was letting through too many paraphrased headlines)
- TF-IDF cosine similarity. Threshold 0.45, catches rewrites with different word order
- Shared named phrases. Two-word proper noun sequences that appear in both titles
- Shared threat actor + token. If both articles name the same APT group and share another meaningful term, that’s a duplicate regardless of how differently the rest of the sentence is phrased
Vendor/product de-duplication was added and then partially walked back; it was flagging too many legitimately distinct stories about the same product. The current implementation is more conservative about that signal.
Temporal conflict detection is unchanged: titles referencing different months or years are never compared, which prevents “March Patch Tuesday” from blocking “April Patch Tuesday.”
DEFCON scoring algorithm
This is the part that’s evolved the most since my first version went live.
v1
Update: v1 has been completely phased out and removed from the code base.
v1 (still the default) works with four equally weighted dimensions, 25 points each, summed to a 0–100 score.
- Volume. New articles compared against a rolling baseline of 12/hour
- CVE severity. Average CVSS scores extracted from article text via regex
- Impact. Signals like “X million users affected” or references to critical infrastructure
- Keywords. Tiered threat vocabulary, where zero-day and nation-state carry more weight than generic terms like “vulnerability”
It’s deliberately simple. You can look at any score and trace exactly which articles pushed it up. No black boxes.
v2
v2 is where things get more interesting. The core insight was that a single high-confidence article, say, a CISA KEV addition or an actively exploited RCE, should be able to drive the score on its own, rather than waiting for a volume spike to move the needle. So v2 introduces decisive triggers.
Each article is scored on two tracks. Track A fires when a trigger pattern is detected. Things like active_exploitation, kev_addition, confirmed_breach, apt_campaign, critical_scope_vuln, or malware_campaign. It immediately anchors the score at a meaningful baseline (55–70 points depending on trigger type). Track B is the familiar stacking approach from v1. The article’s final score is the higher of the two.
The global score then takes a weighted maximum across all articles in a 24-hour window, rather than an average, which means a genuinely serious article doesn’t get diluted by a quiet news day.
There’s also a new sticky level mechanism: when the score drops, it doesn’t immediately snap back to Fade Out. Instead, the level steps down one notch at a time, with a three-hour cooldown between each step; so a genuine DEFCON 2 alert can’t vanish from the dashboard inside an hour just because the news cycle moved on.
You switch between the two versions with a single environment variable: SCORER_VERSION=v1 or SCORER_VERSION=v2. v1 remains the default for now. I think I like v2 more.
DEFCON map
The score maps to five named levels that borrow their names directly from the US military alert system. “LOW” and “CRITICAL” felt too generic for something built around a DEFCON aesthetic. Scores map to levels like this:
| Score | Level | Name | Colour |
|---|---|---|---|
| 80–100 | DEFCON 1 | Cocked Pistol | White |
| 60–79 | DEFCON 2 | Fast Pace | Red |
| 40–59 | DEFCON 3 | Round House | Amber |
| 20–39 | DEFCON 4 | Double Take | Green |
| 0–19 | DEFCON 5 | Fade Out | Blue |
Every article also gets its own score computed the same way, so you can see at a glance which stories are dragging the global level up.
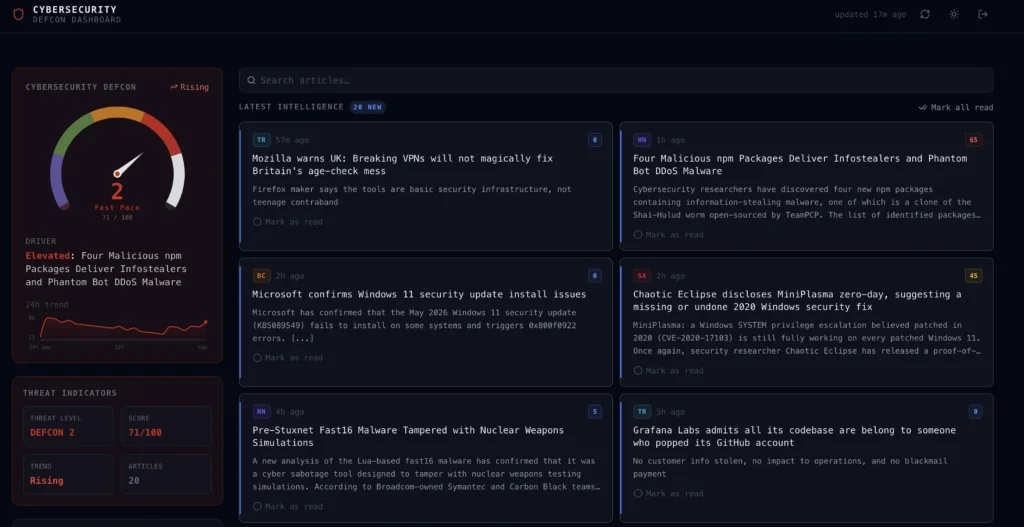
Gauge
The needle is drawn in SVG. The arc spans 240 degrees like a speedometer, split into five equal 48-degree color segments. The needle angle maps linearly from score 0 (150°, eight o’clock) to score 100 (30°, two o’clock). Underneath the gauge, four mini progress bars show the factor breakdown, and a 24-hour sparkline built with Recharts shows how the score has been trending.
Quick start
Get a local dev up and running with podman or docker:
# Clone and create your .env
cp .env.example .env
# Edit .env to suit your needs
# Start everything
podman compose up -dThe front-end is on localhost:3000. The aggregator runs its first fetch cycle immediately on startup, so you’ll have articles within a minute or so.
Clean reset (drops all data):
podman compose down -v && podman compose up --build -dCheck the repo for your production setup.
Wrapping up
Is this project necessary? No. Does it tell me anything I couldn’t get from just opening my RSS reader? Mostly no. But it’s running on my server, it’s mine, and watching the needle creep toward Cocked Pistol during a busy news week scratches an itch that I didn’t know I had.
The scoring algorithm is deliberately simple: regex and keyword matching, not machine learning. That means it’s fast, auditable, and predictable. If the score spikes, I can trace exactly which articles and which dimension caused it. For a personal threat awareness tool, I’ll take legibility over sophistication every time.
The code is on GitHub if you want to run it yourself or rip out just the de-duplication pipeline for something else.
Next
More cyber! I’m getting a taste for it.